5-min Paper: Should you use float or ints as confidence number
TL;DR: Yes, the format matters. When you ask an LLM to output confidence as a decimal (0.00–1.00) versus an integer (0–100), you get measurably different behavior, and not in the direction you’d expect. Decimal format tends to produce lower confidence scores for dubious claims, making it the more conservative (and arguably more useful) choice. But there’s a catch: some models completely break when forced into integer mode on nonsense inputs.
The Question
If you’re building a pipeline where an LLM classifies text and attaches a confidence score, you have a seemingly trivial design choice: do you ask for 0.85 or 85?
Most developers pick one without thinking about it. But here’s the thing; LLMs don’t actually “understand” numbers. They predict tokens. And the token 0. is a fundamentally different object than the token 85 in the model’s embedding space. So what happens when that prefix biases the rest of the generation?
The Hypothesis
Tokenizers (like OpenAI’s) split 0.98 into two tokens: 0. and 98. My hypothesis was that the 0. prefix acts as a kind of anchor, the model “sees” it as small, and compensates by producing a higher number after it. In other words: decimal format should inflate confidence scores compared to integer format, because the model is fighting against the low-magnitude prefix.
Spoiler: the data tells a more nuanced story.
Setup
The experiment is deliberately minimal. One context passage (about the Linux kernel), three types of labels, two output formats, four models, ten repetitions per condition.
Context: A short factual paragraph about the Linux kernel.
Labels (3 types):
- **Truth: “**The Linux kernel is a foundational piece of software written in C.” — Clearly correct.
- **Dubious: **“Linux is the most popular operating system for desktop gamers worldwide.” — Plausible-sounding but misleading.
- **Nonsense: **“The Linux kernel is a species of deciduous tree found in Finland.” — Obviously wrong.
Format conditions:
- **Decimal: **The model fills in a value between 0.00 and 1.00 (scaled to 0–100 for comparison).
- **Integer: **The model fills in a value between 0 and 100.
The prompt structure was: [CONTEXT] + {"label": "...", "confidence": — and the model completes only the number. No chain-of-thought, no reasoning, just the raw confidence value. Each condition was run 10 times per label (30 per label type × format × model).
Models tested: GPT-5.2 (OpenAI), Qwen3-Next-80B-A3B (Alibaba), Llama 4 Maverick 17B (Meta), and Gemma 3n E4B (Google) — all via Together.ai. Two additional models (GPT-5-mini and GPT-5-nano) were tested but returned empty responses across all 180 runs each, so they were excluded.
Results
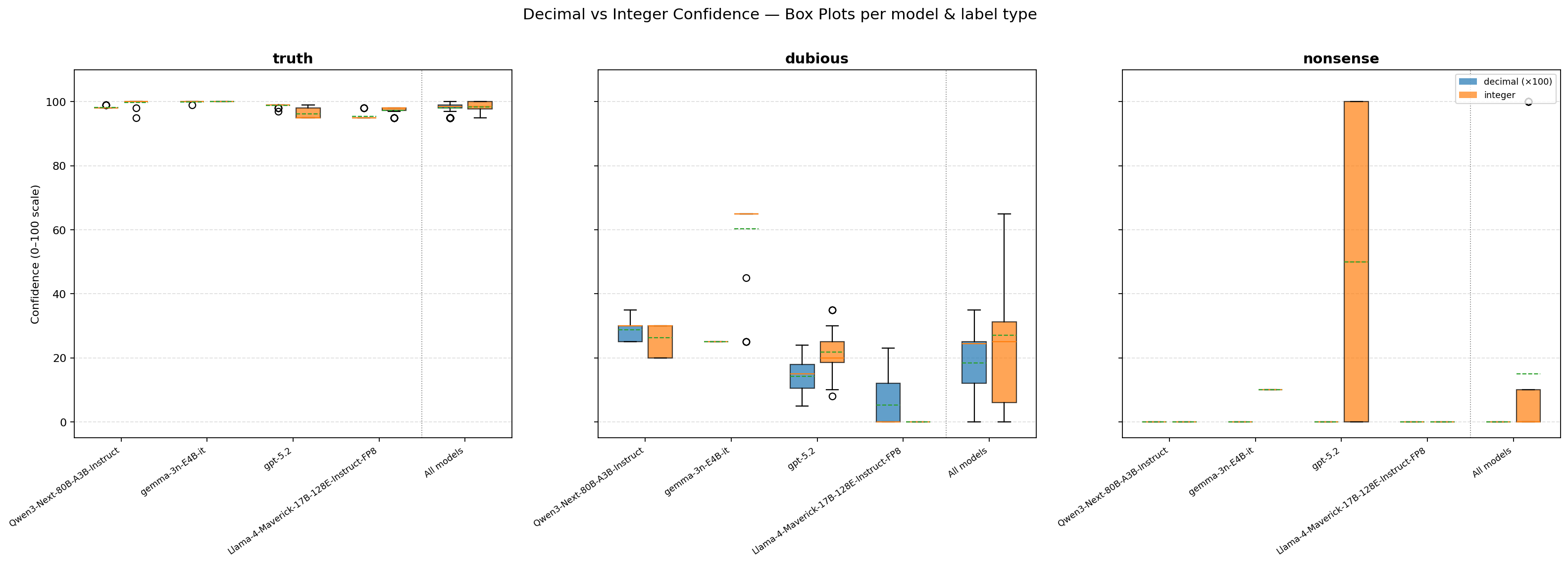
Truth labels: No meaningful difference
All four models gave high confidence for the true statement regardless of format. Means ranged from 95.4 to 100.0 across all conditions. The difference between decimal and integer format was negligible — at most a couple of points. When a claim is obviously true, the format doesn’t matter.
| Model | Decimal (×100) | Integer |
|---|---|---|
| GPT-5.2 | 98.8 | 96.1 |
| Qwen3 | 98.2 | 99.8 |
| Llama 4 | 95.4 | 97.3 |
| Gemma 3n | 100.0 | 100.0 |
Dubious labels: This is where it gets interesting
For the dubious claim, a clear pattern emerges — but it’s the opposite of what I predicted.
| Model | Decimal (×100) | Integer | Δ (int − dec) |
|---|---|---|---|
| GPT-5.2 | 14.3 | 21.8 | +7.6 |
| Qwen3 | 28.8 | 26.3 | −2.5 |
| Llama 4 | 5.3 | 0.0 | −5.3 |
| Gemma 3n | 25.0 | 60.3 | +35.3 |
GPT-5.2 and especially Gemma 3n assigned higher confidence in integer mode. Gemma 3n is the extreme case: a rock-solid 25.0 in every single decimal run (zero variance), but a mean of 60.3 with integers — it jumped to outputting 65 in 27 out of 30 runs. The 0. prefix didn’t inflate the number; if anything, it suppressed it.
My original hypothesis was backwards. The 0. token doesn’t make the model compensate upward — it seems to anchor the model toward the lower end of its confidence range. The decimal format produces more conservative estimates.
Nonsense labels: The breaking point
For the obviously false statement, decimal format worked perfectly — every model returned 0.00 across all runs. Clean, correct, unanimous.
Integer format is where things fell apart for some models:
| Model | Decimal (×100) | Integer |
|---|---|---|
| GPT-5.2 | 0.0 | 50.0 (std=50) |
| Qwen3 | 0.0 | 0.0 |
| Llama 4 | 0.0 | 0.0 |
| Gemma 3n | 0.0 | 10.0 |
GPT-5.2’s integer results for nonsense are wild: it alternated between 0 and 100, producing a mean of 50 with a standard deviation of 50. It literally could not decide. Half the time it said “completely confident” in a claim about the Linux kernel being a tree. Gemma 3n consistently outputted 10 — not catastrophic, but still wrong when the decimal version got a perfect zero.
Qwen3 and Llama 4 handled both formats correctly on nonsense, returning 0 across the board.
Decimal format produces tighter agreement — both within and across models
Beyond the per-model results, decimal format consistently produces more agreement — both across models and within repeated runs of the same model. The effect is strongest where it matters most: on ambiguous and incorrect inputs.
| Metric | Label Type | Decimal | Integer |
|---|---|---|---|
| Cross-model range | Dubious | 23.6 | 60.3 |
| Cross-model std | Dubious | 10.7 | 24.9 |
| Cross-model range | Nonsense | 0.0 | 50.0 |
| Cross-model std | Nonsense | 0.0 | 23.8 |
| Avg within-model std | Dubious | 3.7 | 6.1 |
| Avg within-model std | Nonsense | 0.0 | 12.7 |
In short: if you need reproducible scores or plan to compare confidence across models, decimal format gives you a much tighter distribution to work with.
What’s Is Probably Happening?
The tokenization hypothesis was on the right track but the direction was wrong. Here’s a revised interpretation:
The 0. prefix doesn’t just set a magnitude — it sets a regime. When a model starts generating after 0., it’s in “probability space” where the semantics of the decimal are well-learned from training data. Probabilities between 0 and 1 are everywhere in technical text, and models have strong priors about what values make sense in that range.
Integer confidence scores, on the other hand, are less constrained. The number 65 after "confidence": could mean anything — it’s just a number. Without the 0. anchor pulling the model into probability-reasoning mode, some models default to cruder heuristics. Gemma 3n latches onto 65 as its “unsure” integer. GPT-5.2 oscillates between extremes when it has no confidence, because in integer space it hasn’t learned a clear “zero confidence” response.
Practical Takeaways
Use decimal (0.0–1.0) format for confidence scores. It produces more conservative estimates for ambiguous inputs, more consistent outputs across models, and avoids the catastrophic failures seen with integer format on nonsense inputs. The 0. prefix appears to activate better-calibrated probability reasoning in the model.
If you must use integers, test your specific model on adversarial/nonsense inputs. Qwen3 and Llama 4 handled integers fine; GPT-5.2 and Gemma 3n did not.
Don’t trust confidence scores blindly regardless of format. Even in the best case (decimal format), four different SOTA models gave four different confidence levels for the same dubious claim — ranging from 5.3 to 28.8. These numbers are not calibrated probabilities. They’re token predictions shaped by vibes.
Limitations
This is a 5-minute paper, not a rigorous study. One context, three labels, four models, ten repetitions. The effect could be context-dependent, prompt-dependent, or temperature-dependent. The 0./98 tokenization split is specific to certain tokenizers and may not apply to all models tested. A proper follow-up would test dozens of contexts, vary temperatures, and examine logprobs directly.
But as a quick sanity check for anyone building LLM pipelines: yes, this design choice matters, and decimal wins.
Want to read more articles like this? Check out my personal blog!
Source code + data can be found here
Models tested via Together.ai and OpenAI API on February 7, 2026. Raw data: 1,080 completions across 6 models (4 functional, 2 returned empty responses). No reasoning tokens were used — models produced only the confidence number.
Felix Koole
I’m Felix. I study AI, work in generative engine optimisation, and spend too much time thinking about how LLMs decide what to say.
My path here is a bit non-linear. I spent five years building websites and doing SEO as a freelancer, which gave me a solid intuition for how search works. Then AI search started eating traditional search, and I found myself uniquely placed at the intersection of both worlds — someone who understands the SEO side and has the technical background to reason about the models themselves.
I graduated with a BSc in Artificial Intelligence from Utrecht University in 2025 (officially called Kunstmatige Intelligentie, which I think sounds better). I’m currently doing a Research Master in AI, which I expect to finish in 2028 — assuming I don’t get too distracted by whatever GPT-n just dropped.
By day I’m an LLM Visibility Engineer at PromptMarketing in Amsterdam, where we help brands get cited and surfaced by AI systems. By night I run experiments, write up what I find, and publish it here and on Substack and HackerNoon.
My bachelor thesis was on multi-task learning for medical image segmentation — specifically training a U-Net to segment polyps from colonoscopy images without getting confused by blue dye markers. These days my experiments are less about polyps and more about why ChatGPT recommends one brand over another.
If you’re an SEO specialist trying to make sense of the GEO transition, most of what I write is aimed at you.